At ArcFusion, we believe in learning out loud. We share what we build, how we build it, and what we learn along the way. This post is adapted from one of our internal engineering knowledge-sharing sessions.
By Phasathorn Suwansri (Lukkid) · May 18, 2026
When AI adoption starts to break
AI adoption rarely breaks all at once. It gets messy first.
Take the CFO. AI spend is up 4x this year. Finance asks for a breakdown by business unit. Engineering can show the total, but not the details. Each team tags usage differently, so the answer comes back as a manual spreadsheet exercise, or as a one-off script a developer wrote to stitch the numbers together. And even that falls apart the moment an agent ships without any tagging at all.
The CIO has a different problem. An internal Q&A bot gives someone a snippet from a confidential document they should not have seen. The scary part is not just that one bot failed. It is not knowing whether the other bots have the same issue.
The CTO sees it from another angle. The company started with two agents. Now there are fifteen. Some went through review. Some did not. Nobody has one current list of what is live, who owns it, or what data it can touch.
Different roles, same root cause. The company is no longer experimenting with AI. It is operating AI at scale, and that needs a different playbook.
How companies drift here
No one sets out to lose track of their AI systems. The drift happens gradually as the agent count grows, and it follows roughly the same pattern in every organization we have worked with.
-
Early phase (1–5 agents) — manual coordination is enough. Teams pick a tracking tool like Langfuse, set up evals, write guardrails, and ship. The team is small enough to hold the whole picture in their head, and there is one set of conventions because there is only one team writing them.
-
Growing (10–20 agents) — most teams stay on the same tool. The tool is still fine. What changes is that every team starts using it differently. Different tags, different metadata, different eval coverage. No one agreed on a standard because no one had to.
-
At scale (20+ agents) — the cracks open up. Not because the tool got worse. Because operational complexity does not grow linearly with the number of agents. It compounds.
A quick note on the numbers. The thresholds in this post - five, ten, twenty agents - are illustrative, not precise. The real inflection point depends on your team size, regulatory exposure, and how disciplined your conventions are. Some teams hit the wall at twelve. Others coast to forty. The pattern is what matters, not the exact count.
Figure 1. Complexity does not grow linearly with agent count
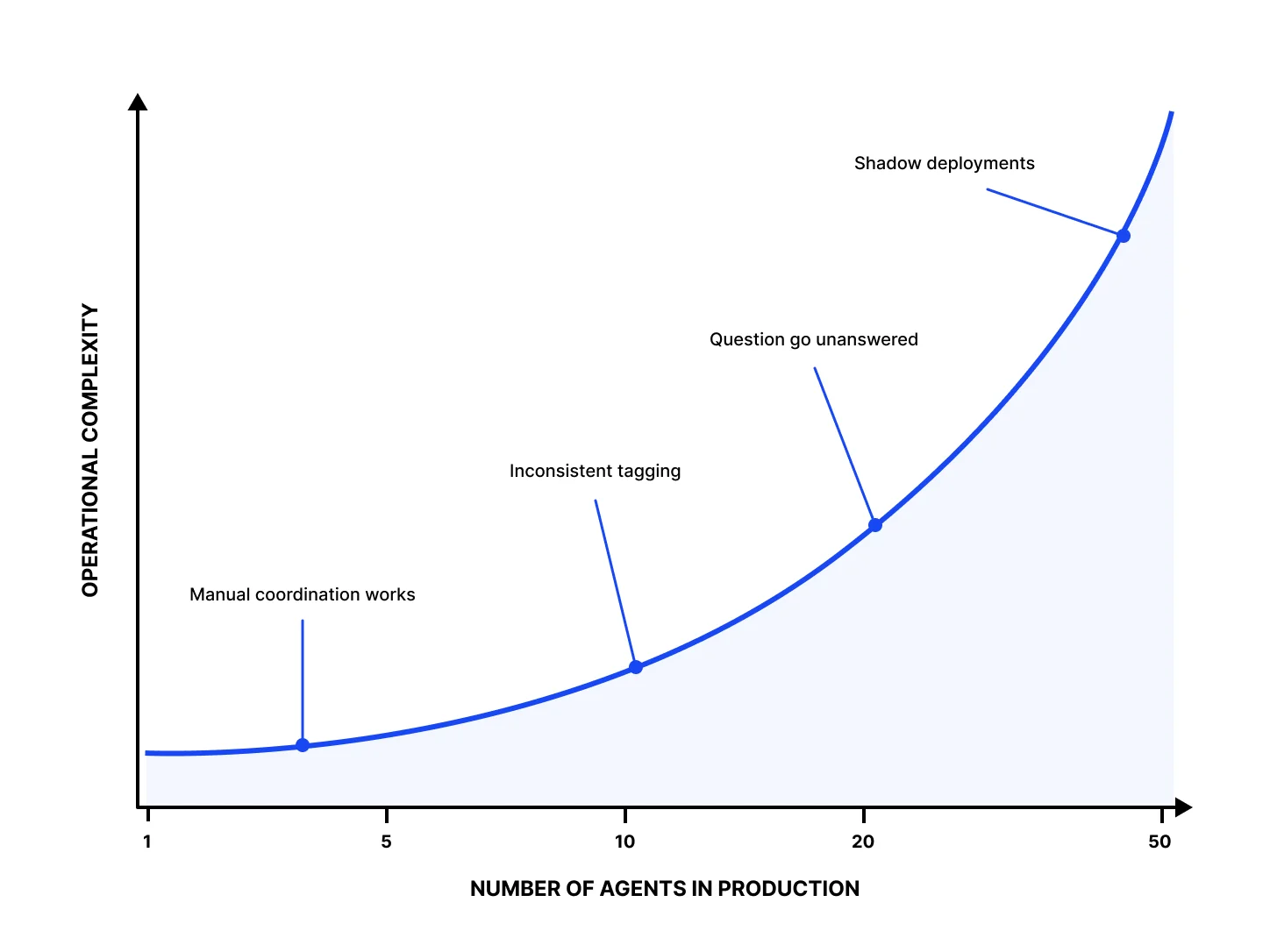
Figure 1. Each new agent adds more operational surface area than the one before it. By the time an organization is running twenty, the work needed to keep visibility, governance, and cost attribution healthy has already grown faster than the headcount supporting it.
The problem at this stage is not monitoring. Most teams have monitoring. The problem is that the monitoring lives in fragments. There is no shared contract that every agent builds against. No central registry that every agent has to live in. No required metadata that would let finance ask one question and get one answer.
Each team meets its own bar, and there is no bar above them.
This is the centralization gap. Closing it requires something that enforces a standard, not a wiki page that everyone is supposed to follow. The piece of infrastructure that does this enforcement is what we call an AI Governance Service.
What an AI Governance Service actually is
An AI Governance Service is middleware that sits between every AI request your company makes and every AI provider you use. Every prompt, every response, and every dollar of spend passes through it.
Think API gateway, but for AI.
You already have an API gateway in front of your services. The reason it exists is the same logic that drives this design. You did not want every team rebuilding rate limits, auth, and logging on their own, so you put one layer in front, and every service inherited the controls automatically.
The same idea applies here, with a different set of controls. Identity. Budget. Catalog approval. Guardrails. Cost attribution. PII scrubbing. Every one of those is enforced at the platform, not inside the agent.
Figure 2. The two checkpoints
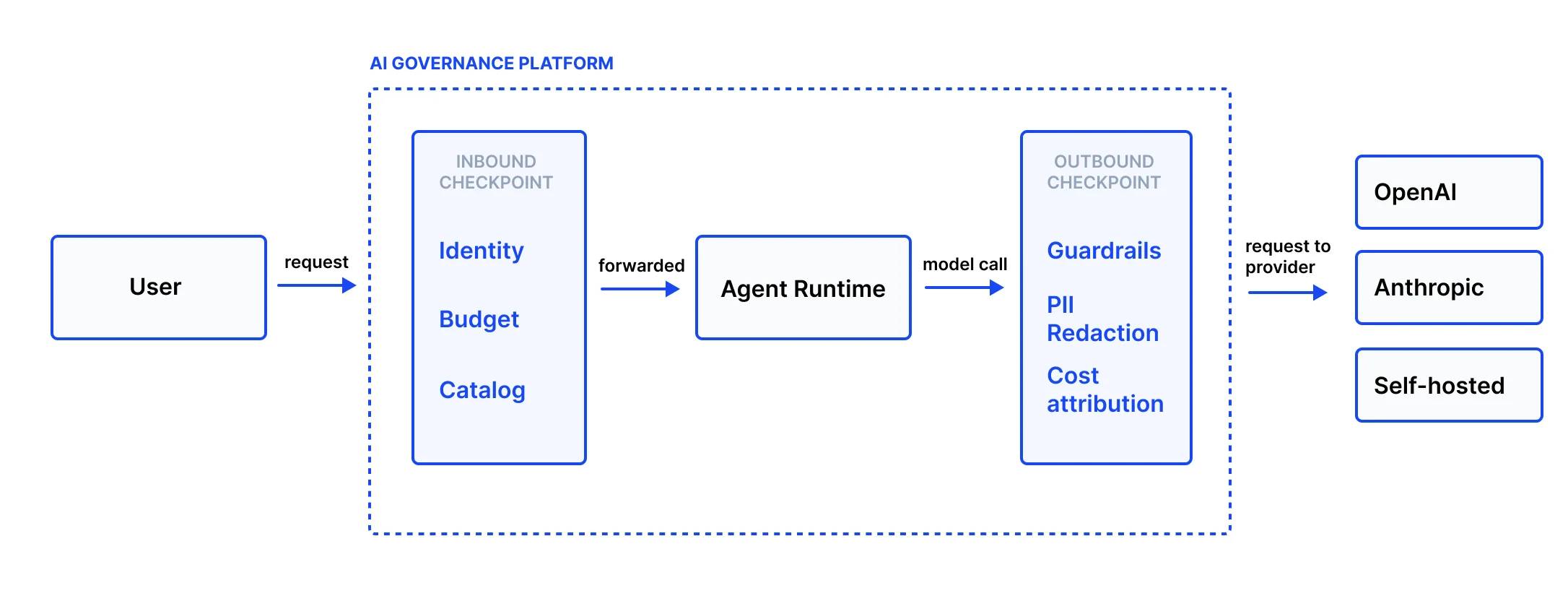
Figure 2. Every request crosses two checkpoints. One on the way into the platform, one on the way out. Everything between them inherits the same governance, including agents that have not been built yet.
How a single request moves through the platform
Imagine an employee opens the company's internal chat, the same place they ask the IT bot about VPN issues, and types something like "summarize last quarter's earnings report and pull the headline numbers." Here is what the platform does before they see an answer.
The inbound checkpoint
Before the request reaches any agent, the platform asks two questions. Who is making this request, and is their team allowed to spend money right now? Is the agent they are calling actually registered and approved?
Identity resolves to a team. The team's monthly budget is checked against current spend. If the budget is exhausted, the request is rejected at the gateway. Nothing further runs. No agent code executes, no model call goes out, no external cost is incurred. This matters because most companies only discover overspend after the invoice arrives. The platform stops the spend at the moment of attempted spend.
The agent check carries equal weight. Every agent has to be registered in the catalog before it can be called. Every change to an agent, including a prompt change, enters a pending state in an approver queue. A reviewer sees what changed, approves or rejects, and only then does the new version become callable. The workflow is closer to a code review than a settings change, and the audit trail covers every version and every approval. This is how you stop "I just tweaked the prompt a little" from quietly turning into a compliance gap.
If both checks pass, the request is forwarded to the agent.
The outbound checkpoint
The agent does its work. It may call other agents, call tools, or eventually call a language model. Every call to a model passes through a second checkpoint before leaving the platform.
This is where guardrails get applied. PII filtering. Prompt-injection defense. Content policy. The property that matters most is the order of evaluation. Organization-level rules apply first, then agent-level rules sit on top. If the organization has blocked a topic, no individual agent can override it, even if its own configuration says otherwise. The org policy wins every time.
On the way back, cost is attributed at the token level to the right team, user, agent, and model. When finance later asks for AI spend by business unit, the answer is a dashboard rather than a spreadsheet exercise.
Two checkpoints carry the whole design. Inbound stops the spend before it happens. Outbound cleans the data before it lands anywhere.
A real example: governing AI
To make this concrete, here is how it looked for one of our clients.
The situation. A client had adopted LibreChat as its internal AI interface. Developers across business units were building custom agents on top of it. Usage was real and growing, but production was blocked. Compliance would not let any of it go live until the governance gaps were closed.
What they needed. Four things had to work at the infrastructure layer, not inside individual agents:
- Approval workflows — every new or updated agent went through review before it could be called.
- Cost tracking — visibility down to the token, with hard budget caps that block requests before hitting an external provider.
- Organization-level guardrails — applied consistently across every interface and agent, with PII stripped from compliance logs before storage.
- Red team evaluation — ran in CI on every deployment, with results tracked over time rather than collected once for an audit.
These requirements are typical for a regulated company. The constraint that made the problem interesting was the insistence that all of it had to live in the infrastructure, so the controls would still apply to agents that had not been built yet.
What we built. We used LiteLLM as the routing core. It handles multi-provider routing and exposes a unified API regardless of whether the backend is GPT, Claude, or a self-hosted model. The governance logic layered on top.
The architecture settled into three zones:
- Governance and gateway — API routing, agent discovery, budget enforcement, and guardrails.
- Runtime — individual agents running in Docker containers.
- Evaluation — the red team runner, prompt evaluation CI, and the agent catalog with its approval queue.
Cost ingestion ran through Langfuse, with full metadata captured on every request, including which agent, which user, which model, token counts, tools called, and total attributed cost. The FinOps dashboard surfaced spend at four levels of granularity: organization-wide daily spend, per-agent cost, per-user consumption, and per-model breakdown.
What changed. Finance can now pull cost by business unit without a spreadsheet exercise. Compliance has consistent guardrail coverage across every agent, including the ones built after the platform shipped. Every prompt change goes through an approver before becoming callable, with an audit trail across versions. The infrastructure carries the governance, so individual agents no longer have to remember to.
Who needs this today
This kind of platform is not for everyone. Below twenty agents, manual coordination usually still works if the team is disciplined. Above twenty, it tends to stop working regardless of discipline.
The companies hitting that wall first are in regulated industries, where compliance forces the visibility question earlier. Banking, insurance, and telecom are the most common. After that, any company running twenty or more agents in production tends to land in the same conversation. And after that, it is any organization where finance has started asking AI-cost questions that engineering cannot answer.
The clearest signal that you are past the line is when your CFO sends a message asking why the AI bill doubled and your engineering lead cannot answer the same day.
If you are not there yet, this is not the time to build it. Stay light, ship things, and come back to this post in six months.
Tools in the market
You do not have to build this from scratch. A few options are worth a look.
| Tool | Type | Best for |
|---|---|---|
| LiteLLM | Open source | Getting a gateway running in a week — solid multi-provider routing and a broad community. |
| Portkey | Open source / Commercial | Teams that want opinionated guardrails and governance defaults out of the box. |
| Bifrost | Open source | High-volume traffic where latency matters. |
| Helicone | Open source / Commercial | Observability alongside an existing gateway — pairs well with LiteLLM. |
Why we built our own stack on top

We tried all of these tools on real client deployments. Each does part of the job. None of them did all of it the way regulated enterprises actually need, so we built our own layer on top.
Two specific gaps pushed us in that direction:
- Infrastructure cost tracking — most tools track AI cost at the token level but not infrastructure cost alongside it. For chargeback to business units, our clients needed both numbers in the same ledger, so we built a layer that connects virtual-key spending to the business-unit hierarchy and integrates infra cost into the same view.
- Catalog with approval workflow — we wanted every asset — agents, models, and MCP tools — reviewed and approved before reaching users. Code-review-style review on every change, with a full audit trail across versions. The off-the-shelf tools did not do this.
Closing
The problem is not having twenty agents.
The problem is when no one can answer the basic questions. Which agents are live. Who owns them. What data they can access. How much they cost. What happens when one of them goes wrong.
At five agents, discipline is enough. At ten, the cracks start to show. At twenty, finance, security, and leadership tend to start asking questions the team cannot answer quickly.
That is the point where AI stops being a collection of experiments and becomes infrastructure. And infrastructure needs a system of record.
The real question is not whether to build or buy. The better question is what needs to be centralized before AI adoption outgrows your ability to see it.
If your organization is scaling AI agents and needs better governance, cost visibility, or production-ready infrastructure, we would be happy to discuss. Reach out at info@arcfusion.ai.