

At ArcFusion, we believe in learning out loud — sharing what we build, how we build it, and what we learn along the way. This post is adapted from one of our internal engineering knowledge-sharing sessions.
Image generation is a game-changer for marketing. Need a model holding your product on a sunlit beach, or in a cozy café? Done in seconds. But there's a catch: AI doesn't care about brand guidelines. All too often, your crisp product turns into a distorted blob — or worse, the wrong product entirely.
We hit this exact wall while building a campaign generator. Our generative model was great at "vibes" but it had no concept of product integrity. To fix it, we built an image-processing QA layer using SIFT (Scale-Invariant Feature Transform).

The Problem: More Themes, Infinite Ways to Fail
The campaign website needed to generate images featuring a person interacting with a product — lifestyle shots where the product is visible but integrated naturally. The generative pipeline accepts a base image (the person) and a product reference image, then produces a composite.
With a single theme, this works reasonably well. Across multiple themes, scenes, and poses, the failure modes multiply. Products appear too small to identify. The model places them behind hands or arms. Proportions drift — a tall slim bottle becomes squat, or a wrapper's aspect ratio warps. In our initial runs, roughly 35–40% of generated images had at least one product placement issue that would be unacceptable for a public-facing campaign.
Manual review of every generated image wasn't viable at the volume the campaign required. We needed automated quality control that could catch failures and trigger regeneration before a human ever saw the output.
Why Classical Image Processing, Not Deep Learning
The instinct might be to train a classifier or object detector to verify product placement. We considered this, but two practical constraints pushed us toward classical feature matching instead: training a reliable detector requires labeled data for every product in the catalog, and the inference cost would stack on top of an already GPU-heavy generative pipeline.
SIFT, by contrast, needs only a single reference image per product. It extracts keypoints that are invariant to scale, rotation, and moderate affine transformations — exactly the kinds of distortions our generative model introduces. The approach is old-school, but it gave us a zero-shot product verification system that works the day a new product is added to the catalog.
The SIFT Pipeline: From Keypoints to Product Verification
The verification pipeline runs on every generated image before it's approved. Here's how the stages connect.
Keypoint Extraction with Scale-Space Analysis
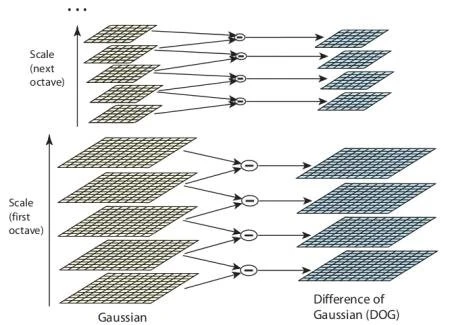
SIFT works by constructing a Gaussian scale space — the input image is progressively blurred at multiple scales, and adjacent scales are subtracted to produce Difference of Gaussian (DoG) images. Local extrema in the DoG images become candidate keypoints. Each keypoint gets a 128-dimensional descriptor built from gradient histograms in its local neighborhood.
For our use case, we extract keypoints from both the reference product image and the generated campaign image.
Feature Matching with FLANN
We match descriptors between the reference and generated images using FLANN-based matching, which is more efficient than brute-force search for larger sets of SIFT descriptors. To filter out weak matches, we apply Lowe's ratio test: a match is accepted only if the distance to the best match is sufficiently smaller than the distance to the second-best match.

Decision Logic: Accept, Replace, or Regenerate
The match count drives the decision tree. Through experimentation on our generated outputs, we found that both unusually low and unusually high match counts can signal failure modes.
- Too few good matches usually means the intended product is effectively absent — either missing entirely, too distorted, or too small to verify reliably. These images are flagged for full regeneration.
- A moderate number of good matches is the expected range for a valid single-product placement. The product is likely present, but may still have occlusion or proportion issues. In this range, we attempt a product replacement step by estimating a homography from the matched keypoints and warping the reference product into place.
- Too many good matches can indicate a different kind of problem: the image may contain multiple product instances or repeated product-like regions. Because this makes the result ambiguous, we do not pass these images directly. Instead, they are routed for additional checks or regeneration.
The Product Replacement Step
When an image falls into the replacement range, we use the estimated homography to warp the reference product into the generated scene and create a corresponding mask for the replacement region. We then compare the warped product against the generated image within that masked area. If subtracting the two leaves too much residual signal, we treat that as a sign that the product is not cleanly recoverable.
In practice, this usually means one of two things: either the generated product itself is distorted, or part of it is being covered by a hand or fingers. In both cases, the warped reference fails to align cleanly and leaves visible residual traces. We treat both as product distortion and route the image to regeneration instead of replacement.
What We Learned
Building this system reinforced something we keep rediscovering: generative AI is strongest when paired with deterministic verification. The creative model is excellent at producing visually compelling images, but it has no concept of product fidelity. Classical image processing fills that gap precisely because it isn't creative — it rigidly compares what was generated against what should have been generated.
The SIFT-based approach also taught us that classical algorithms scale better than we expected in a production generative pipeline. Adding a new product requires only a new reference image — no retraining, no fine-tuning. The entire QA pass runs on CPU, which keeps resource usage low while still providing effective verification.
References
- Lowe, D. G. (2004). "Distinctive Image Features from Scale-Invariant Keypoints." International Journal of Computer Vision, 60(2), 91–110.
- OpenCV Documentation — SIFT (Scale-Invariant Feature Transform)
- OpenCV Documentation — Feature Matching with FLANN
- OpenCV Documentation — Homography
Building a generative pipeline that needs to hold up to brand scrutiny? The ArcFusion team works with enterprises across Southeast Asia to pair creative AI with the verification layers that make it production-ready. Reach out to us at arcfusion.ai.


